Knowledge QA using Retrieval Augmented Generation (RAG)
Implement a RAG Workflow with OpenAI, Langchain, ChromaDB

Summary
In this post, we implement an application of the Retrieval Augmented Workflow to create a bot that answers questions on the NDIS Price Guide. This is one way to leverage the capability of LLMs on data they haven't been trained on.
The code is available here: https://gist.github.com/IsisChameleon/e88b00731f20bba8a71d7a3d4eebad59
Introduction
With the ever-increasing volume of data being generated daily, organizations face the daunting task of extracting valuable insights to make informed decisions.
Large language models are powerful interpreters of natural language queries, but they lack knowledge of private sources of information and even public data produced after their training cut-off date. One way to augment their knowledge is to provide it in their "context window", i.e. the amount of data (including the query) that you can pass into the LLM (entering the vast realm of prompt engineering). Alas, that context window has a limited size: Openai GPT-3.5-Turbo has 4K, GPT-4 has 8K [2] and the largest to date is Claude 2 from Anthropic with a 100K context! [3] Note that the increase in context size also often comes with an increased response time and cost per API call. So, how do we stuff all of our private data in that tiny context? Semantic search to the rescue: semantic search is used to retrieve information relevant to the user query in our private data, and feed only those bits to the LLM context, along with the prompt and user query. According to Wikipedia: "Semantic search denotes search with meaning, as distinguished from lexical search where the search engine looks for literal matches of the query words or variants of them, without understanding the overall meaning of the query. Semantic search seeks to improve search accuracy by understanding the searcher's intent and the contextual meaning of terms as they appear in the searchable dataspace... to generate more relevant results."[1]
Practically, our corpus of text is going to be cut into chunks, and each chunk is embedded using our LLM Model-specific embedding tool. A text embedding is a vector that can measure the relatedness between text strings: each of the dimensions of the embedding vector is a feature of the chunk of text considered "in the mind" of the LLM (that feature will not have a clear correspondence in human language).

The query will also be transformed into that multi-dimensional vector and an efficient vector similarity search algorithm will retrieve the nearest neighbours of the query to form the relevant context.
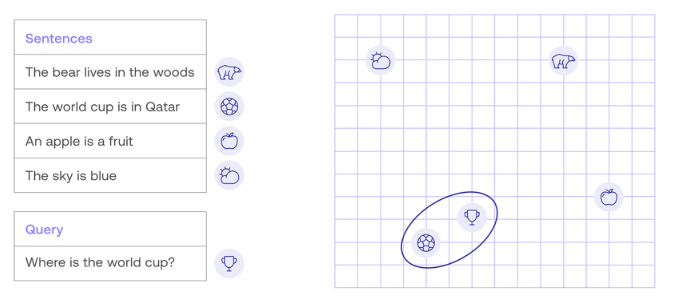
Thankfully, while the embedding is dealt with by the large language model, vector databases (and vector libraries) perform the semantic search by storing the vectors and executing an efficient similarity search.
For more information on:
Semantic search https://docs.cohere.com/docs/what-is-semantic-search
Embeddings: https://www.pinecone.io/learn/vector-embeddings/, https://experiments.withgoogle.com/visualizing-high-dimensional-space
Vector search: https://www.pinecone.io/learn/series/wild/
Application
Description
In Australia, the NDIS (National Disability Insurance Scheme) provides funding to eligible people with disability to gain more time with family and friends, greater independence, access to new skills, jobs, or volunteering in their community, and improved quality of life. When a provider of eligible goods or services wants to invoice an NDIS participant, they are faced with the daunting task of understanding the NDIS price guide rules to determine the correct way to invoice. If they incorrectly submit an invoice, their cash flow will suffer and the participant might be inappropriately charged. Our application is a bot service that will help answer provider queries about invoicing, retrieve the correct item code and maximum price for them and provide guidance on specifics of the NDIS Price Guide. The approach we will take is to use the RAG Workflow.
Process Overview

Step 1. Loading the vector store with the NDIS Price Guide PDF content.
Data Loading: Read text and tables from the PDFs into text documents
Data Processing: Split the text into manageable chunks.
Embedding: Ask the LLM to embed the chunks of data (to create vectors).
Vector store creation: Construct a persistent searchable index of the embedded vectors using a vector database.
Step 2. Upon reception of the user query
Query Embedding: Embed the user's query to create a vector.
Similarity Search: Find the nearest neighbours of the query vector in the vector store.
Build Prompt with Context: Add the retrieved document chunks as context to the prompt for the LLM, alongside the user query.
Answer Generation: Pass the prompt to the LLM to generate an answer.
Implementation
Setup development environment
Please refer to my previous blog to setup a python environment. The only API you need a key for is Open AI (OPENAI_API_KEY), for the embeddings and the query to GPT.
I use the following packages:
langchain = "^0.0.234"
python = "^3.10"
openai = "^0.27.8"
unstructured = "^0.7.5"
tabulate = "^0.9.0"
tiktoken = "^0.4.0"
python-dotenv = "^1.0.0"
ipykernel = "^6.24.0"
streamlit = "^1.24.1"
pdfplumber = "^0.10.2"
Installing Chroma DB
Chroma is an open-source vector database. https://docs.trychroma.com/. Copy the 3 lines below to install it as a local database in a docker container.
git clone https://github.com/chroma-core/chroma.git
cd chroma
docker-compose up -d --build
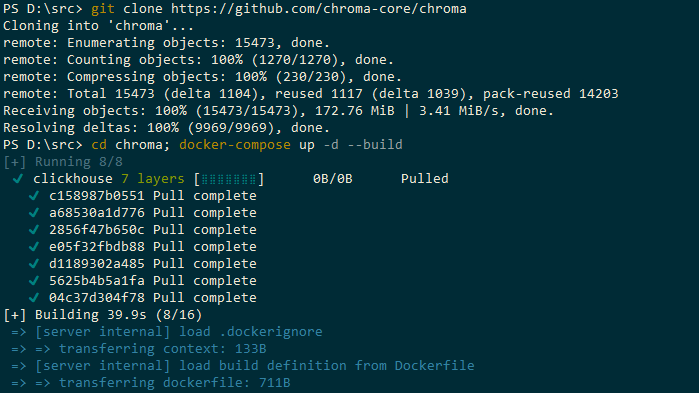
You can quickly check if you can access and if there is no block to access the server API by entering the URL: http://localhost:8000/api/v1/heartbeat
PDF Loader choice
The NDIS Price Guide is a PDF mixing text and tables.
I used ChatGPT Code Interpreter for an initial PDF data analysis. The standard PyPDF2 library was not doing a good job at extracting text and tables, and it was a library used by Langchain in their standard DirectoryLoader.
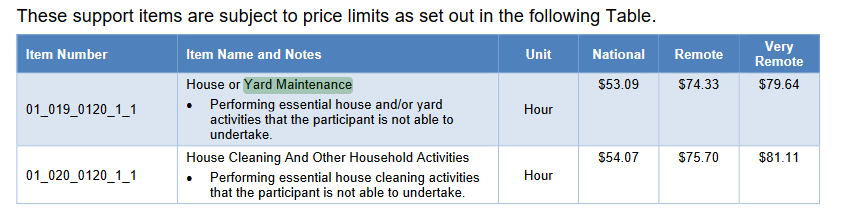
For example, ChatGPT extracts the text using PyPDF2 and using a keyword search, does not find "yard maintenance" while it exists in the original PDF.
The PDF contains Yard Maintenance in a table.
After digging around I found out that PDFPlumber was doing a decent job at extracting all the information, and Langchain had one loader called PDFPlumberLoader.
The following creates a DirectoryLoader to load all csv and pdf files in a directory.
import os
from langchain.document_loaders import CSVLoader
class MyDirectoryLoader:
def __init__(self, dir_path, csv_args={}, **kwargs):
self.dir_path = dir_path
self.kwargs = kwargs
def check_args(self):
print(**self.pdf_args.keys())
def load(self):
docs = []
for root, _, files in os.walk(self.dir_path):
for file in files:
print('file:', file)
file_path = os.path.join(root, file)
if file_path.endswith('.csv'):
loader = CSVLoader(file_path, **self.csv_args)
elif file_path.endswith('.pdf'):
# pages_per_document=self.kwargs.get('pages_per_document', 1)
# loader = MyPDFLoader(file_path, pages_per_document=pages_per_document)
loader = PDFPlumberLoader(file_path)
else:
print(f"Do not process the file: {file_path}")
continue
loaded_docs = loader.load()
docs.extend(loaded_docs)
return docs
Extract the content of your directory using:
loader = MyDirectoryLoader(directory)
docs = loader.load()
RAG Workflow
Part 1. Store your knowledge as embedding vectors
Read PDFs
After loading the PDFs, there is 1 langchain Document per PDF page. This is going to be further split to create smaller chunks, to make sure we can select all the relevant information without exploding the context size of the LLM when running the final user query.
from langchain.text_splitter import RecursiveCharacterTextSplitter
loader = MyDirectoryLoader(directory)
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=128)
texts = splitter.split_documents(docs)
| Before splitting in chunks (docs) | After splitting (texts) |
| Number of documents: 101 | Number of chunks: 354 |
| Average document length in characters:2774.0 | Average chunk length in characters:858.8 |
| Average document length in tokens:652.3 | Average chunk length in tokens:201.9 |
Embed chunks and store them in ChromaDB
All the magic happens in Langchain, by importing a wrapper for ChromaDB as a vector store from langchain.vectorstores import Chroma and running Chroma.from_documents(texts, client_settings=client_settings, embedding = OpenAIEmbeddings(), collection_name=collection_name)
This embeds the text using the default OpenAI embedding function, and stores the vectors in ChromaDB instance determined by client_settings, into the Chroma collection 'collection_name. A collection is where ChromaDB stores your documents, their embeddings and additional metadata.
collection_name = 'NDIS_PDFPLUMBER_1_TEXTS_1024_128' # chromaDB collection name
from chromadb.config import Settings
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
client_settings = Settings(
chroma_api_impl="rest",
# as I run my code into a devcontainer, I cannot simply say ChromaDb host is localhost
# I need to say host.docker.internal to signify "devcontainer host (which is localhost)"
chroma_server_host="host.docker.internal",
chroma_server_http_port="8000"
)
db = Chroma.from_documents(texts, client_settings=client_settings, embedding = OpenAIEmbeddings(), collection_name=collection_name)
And that's it! You now have a persistent embedded representation of your PDF in ChromaDB!
This part of the process is completed.
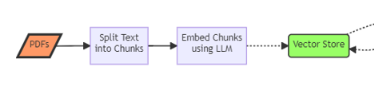
Part 2. Retrieval Augmented generation
We need to collect the user query and pass it along to the LLM in a carefully crafted prompt, that also includes the result of the similarity search. Equipped with all that information, we hope the LLM will provide a satisfactory answer!
To do so, Langchain provides RetrievalQA, a simplified question-answering chain that retrieves relevant documents from a vector database and uses them to answer natural language questions.
In this example, let's build it from scratch using a simple LLMChain component. LLMChain provides a simple interface to format prompts using a template and run them through a language model. It's a core building block in LangChain for chaining LLMs and other components together.
def setup_chain_and_prompts(temperature):
llm = ChatOpenAI(temperature=temperature, model='gpt-3.5-turbo-16k')
template = """
You are a helpful, polite and well-mannered bot, a specialist in the NDIS Price Guide.
to help providers to invoice for their services or the items they have sold to the participant.
I will share a provider's query with you. You will try to understand whether it is a product they sell or a service they perform for a participant.
Upon receiving the user query and the price guide context, your aim is to:
- select for them the approriate item code from the price guide
- determine the maximum price they can charge for the good or service
- more generally, by advising them following recommendations set up in the price guide for that particular service if any
When replying, you will follow ALL of the rules below:
1/ If some information is missing to determine what item code to use, please ask that information to the user
2/ If there is more than one item code matching the given criteria, determine what makes the difference between one item code and another and ask that question to the user
3/ If you otherwise don't have enough information to answer the user query, don't invent anything and say you don't know
Provider query:
{query}
Here are the relevant extracts from the price guide:
{price_guide_context}
Please write the most informative answer to the provider query:
"""
prompt = PromptTemplate(
input_variables=['query', 'price_guide_context'],
template=template
)
chain = LLMChain(llm=llm, prompt=prompt)
return chain
Upon receiving the user query, let's embed it and perform a similarity search in our vector store. results = coll.query(query_texts=[query], n_results=n_results) ... ChromaDB is going to perform a similarity search in the collection coll using query and return the n_results most similar vectors texts and metadata.
Note that ChromaDB and vector stores in general need to know about your embedding method. To retrieve a collection in Chroma you have to specify the original embedding function.
def get_chroma_collection(collection_name):
client_settings = Settings(
chroma_api_impl="rest",
chroma_server_host="host.docker.internal", # when you run this inside a devcontainer you need to explicitely say host.docker.internal to signify "devcontainer host localhost"
chroma_server_http_port="8000"
)
chromaClient = Client(client_settings)
coll = chromaClient.get_collection(name=collection_name, embedding_function=OpenAIEmbeddings().embed_documents)
return coll
def similarity_search(query, coll, n_results=10):
results = coll.query(query_texts=[query], n_results=n_results)
metadatas = [ met for met in results['metadatas'][0]]
docs = [ doc for doc in results['documents'][0]]
return { 'documents': docs, 'metadatas': metadatas}
Finally, running the LLMChain will contact the LLM with the prompt template augmented with the user query and the pdf context returned by the similarity search. Note: n_results determines the number of nearest neighbours of your query vector returned by the similarity search.
def get_query_response(chain, query, n_results=10):
similar_docs = similarity_search(
query,
get_chroma_collection(collection_name),
n_results=n_results)
response = chain.run(query=query, price_guide_context=similar_docs['documents'])
return response
Let's build a Streamlit app to put it all together!
import streamlit as st
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.chains import LLMChain
from dotenv import load_dotenv
from langchain.embeddings import OpenAIEmbeddings
from chromadb.config import Settings
from chromadb import Client
load_dotenv()
collection_name = 'NDIS_PDFPLUMBER_1_TEXTS_1024_128'
# ... def setup_chain_and_prompts, ... etc as above
def main():
st.set_page_config(
page_title="NDIS Provider invoicing helper bot", page_icon=":sun:")
st.header("Invoicing query :sunflower:")
temperature = st.sidebar.slider('Temperature', 0.0, 1.0, 0.5)
query = st.text_area("Please enter your query related to invoicing. Don't forget to provide the location, time and description of your service/item")
if query:
chain = setup_chain_and_prompts(temperature)
st.write("Retrieving price guide information...")
result = get_query_response(chain, query)
st.info(result)
if __name__ == '__main__':
main()
To run the app (called app.py), just type : streamlit run app.py

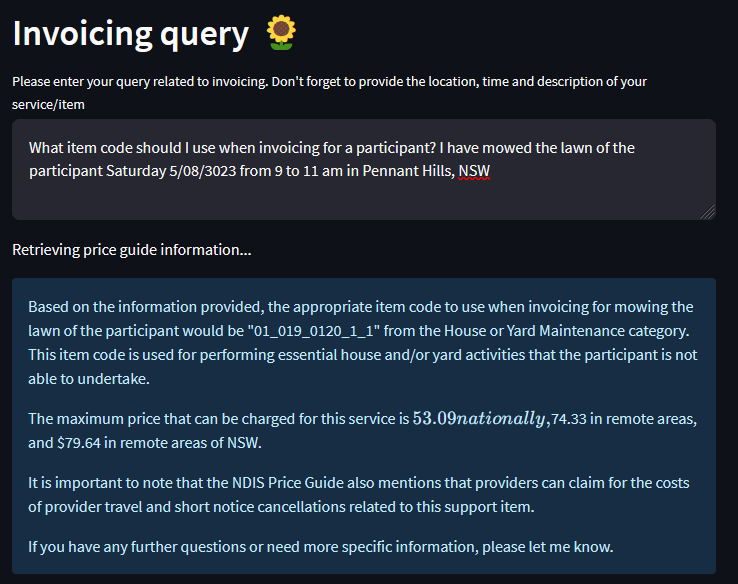
We now have the full workflow completed!
Testing
The following parameters will influence the result:
LLM Model choice | gpt-3.5-turbo-16k |
Model temperature | 0 - 1(*) |
Chunk size and overlap | 1024, 128 |
Data loader | PDF Plumber |
Prompt template | as above |
Similarity search n_results | Number of results returned |
(*) A model temperature of 0 skews the model towards the outcomes with the highest probability, making the results more deterministic. Conversely, a higher temperature infuses the model with randomness, leading to more diverse outcomes. The model temperature didn't have a strong effect in my case.
To test the data loader and chunking strategy [5], I created multiple collections in ChromaDB, directing my app towards one or the other and comparing results. In my experiment, data loading (choice of PDF Plumber) and the size of the chunks had the greatest impact on answer accuracy! When the chunks were too big, I couldn't return enough results in the model context, and it was often having incomplete information to answer the query.
Next steps...
Stay tuned! The next steps include:
. adding memory to create a conversational chatbot
. setting up the app in a cloud
Reference
[1] Wikipedia on semantic search https://en.wikipedia.org/wiki/Semantic_search
[2] Openai GPT-4 https://platform.openai.com/docs/models/gpt-4
[3] Claude 2 https://www.anthropic.com/index/claude-2
[4] Chroma vector database https://docs.trychroma.com/
[5] Chunking strategies https://www.pinecone.io/learn/chunking-strategies/
[6] Semantic search https://docs.cohere.com/docs/semantic-search



