
A journey from LLM Chains to Agents using Langchain (Part 1)
How to get an LLM to solve problems with tools


Part 1 - Chains
LLM Chains are used to statically link multiple LLM interactions to build complex functionality. The Langchain Python library provides a wrapper to connect LLMs and tools from different providers.
The code of this blog is available here: https://gist.github.com/IsisChameleon/3721725b49fd2ab8182cf1057b8f1b72
Basic chain
A chain in Langchain is a construct that allows you to compose calls to LLMs and tools, in a predetermined way. It takes inputs that are embedded into a larger prompt, prompts the LLM (and/or runs a tool, transforms the data ...), and finally produces outputs, which in turn can be used as input for another chain.
For example, the simplest chain takes the user input, includes it in a given prompt template, sends it to the LLM and returns the formatted response to the user.

from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# Select OpenAI default model with a temperature of 0.5
llm = OpenAI(temperature=0.5)
# Create a prompt template
prompt = PromptTemplate(
input_variables=["subject", "type_of_audience"],
template="Please explain {subject} like I'm a {type_of_audience}?",
he )
# Create chain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain
print(chain.run({ "subject": "quantum physics", "type_of_audience": "5 yo"}))
Quantum physics is like a game of hide and seek.
In the game, the person hiding can be in many places at the same time.
This is like quantum physics, where tiny particles can be in many place at the same time.
Adding Memory
How to implement memory when required for the sequence of interactions with the LLM or some tools? Let's take an example with a chatbot conversation. Langchain provides several memory classes for that purpose.
Conversation
In its most basic form, the conversation chain will maintain a memory of the previous conversation and run a simple chain using as input the user request and the conversation history.

from langchain.llms import OpenAI
from langchain.prompts.prompt import PromptTemplate
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
# Choosing LLM
llm = OpenAI(temperature=0.5)
# Defining prompt
template = """You are a great teacher, able to break down concepts simply and adapt to your audience.
Conversation history: {history}
Conversation:
Human: {input}
AI:"""
prompt = PromptTemplate(input_variables=["history", "input"], template=template)
# Setting up a conversation chain with the above prompt and a simple buffer as memory
conversation = ConversationChain(
llm=llm, verbose=True, prompt=prompt, memory=ConversationBufferMemory(llm=llm)
)
# User input
input = "Please explain quantum physics to teenagers"
# Running the chain for the first time
conversation.run({
"input": input
})
Quantum physics is a branch of physics that deals with the behavior of matter
and energy at the atomic and subatomic level. It is a complex subject,
but it can be broken down into simpler concepts.
For example, particles such as electrons and protons have wave-like properties,
meaning they can exist in multiple places at the same time.
This can be used to explain phenomena such as the Heisenberg Uncertainty Principle,
which states that the more precisely you know a particle's position,
the less precisely you can know its momentum."
Now let's ask a second question! It's been formulated with a reference to the previous question to make sure our memory is working.
input = "Can you tell me more about that principle?"
conversation.run({
"input": input
})
We can see in the verbose output below that the prompt presented to the LLM for that second question contains the conversation history in its entirety.

And the response is correctly discussing the Heisenberg uncertainty principle!
Sure. The Heisenberg Uncertainty Principle states that the more precisely you
know a particle's position, the less precisely you can know its momentum.
This is because particles exist in multiple places at the same time,
so it is impossible to know both the exact position and momentum of a particle
at the same time. To give a simple example, if you know the exact position of
a ball, you can't also know how fast it is moving.
Chain composition
Conversation about your data
In the previous blog, we implemented a low-level version of the RetrievalQA chain to ask a question to the LLM about our own PDFs. How do we update that for a conversation? When the user asks for clarification on the first answer for example, how do we retrieve the meaningful information from our vectorstore?
Langchain solves this question by implementing the following chain:

First, an LLM is prompted to reformulate the user request and the related conversation history into a standalone question, that does not require additional context. This question is used to perform a semantic search on the vector store where our documents are embedded and retrieve pertinent information (documents). The LLM is then prompted to answer the standalone question given the documents. As in the previous conversation example, the LLM answer is added to the conversation history, and the user can ask a new question.
First, we set up the vector store using ChromaDB, and openai. By default, the chroma vector store will be in-memory (not persistent) and the collection name is given by Langchain.
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
from langchain.embeddings import OpenAIEmbeddings
from langchain.memory import ConversationBufferMemory
from langchain.vectorstores import Chroma
from langchain.document_loaders.pdf import PDFPlumberLoader, PyPDFLoader
# (1) Setup the vector store
# . choose one of langchain pdf loader to load the pdf text
# . embed and store in the vectorstore
loader = PDFPlumberLoader("/workspaces/IsabelleLangchain/data/blog4/complex-systems.pdf") #<<<<< change your filename here
documents = loader.load()
embeddings = OpenAIEmbeddings()
# This may take a little while as it embeds and loads the documents in the vectorstore!
vectorstore = Chroma.from_documents(documents, embeddings)
Now set up the conversational chain with the 2 subchains as described above:
# Setup conversational qa chain
# . using openai default chat model
# . and a ConversationBufferMemory
# . and our Chroma vector store
llm = ChatOpenAI(model='gpt-4')
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
qa = ConversationalRetrievalChain.from_llm(
llm,
vectorstore.as_retriever(),
memory=memory,
verbose=True
)
query = "What is agent-based modelling?"
result = qa({"question": query})
result
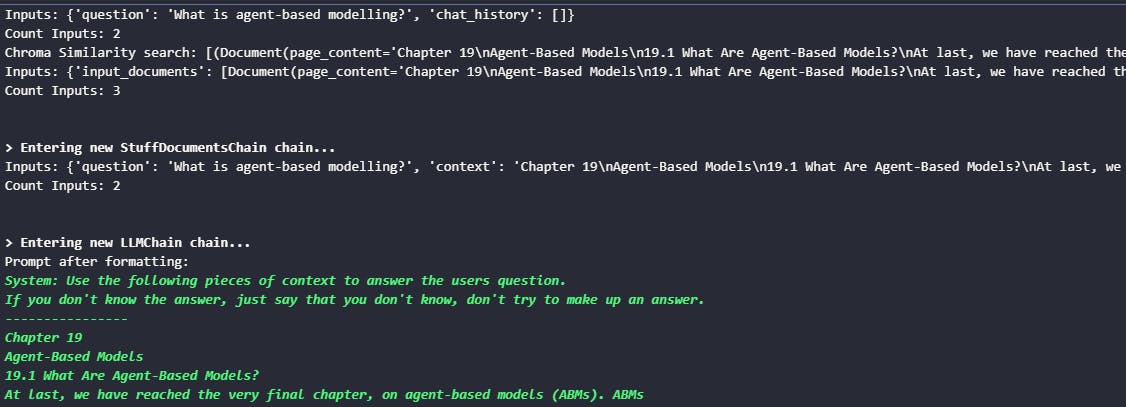
In the result, we can see the user question, the chat history and the answer! So scientific ;)
{'question': 'What is agent-based modelling?',
'chat_history': [HumanMessage(content='What is agent-based modelling?',
additional_kwargs={}, example=False),
AIMessage(content='Agent-based modeling (ABMs) is a computational simulation
method that involves the use of many discrete agents. They are arguably the most
generalized framework for modeling and simulating complex systems, which can
include cellular automata and dynamical networks as special cases.
ABMs are used in various disciplines to simulate dynamical behaviors of systems
made up of a large number of entities. These entities, or agents, can have
complex properties and behavioral rules that are described algorithmically,
allowing for the representation of complex individual traits.
The agents are discrete entities that may have internal states,
may be spatially localized, and can interact with their environment and other
agents. The analysis of ABMs and their simulation results are usually carried out
using statistical analysis. However, the construction of ABMs can be
code-intensive and complex, requiring careful planning and execution.',
additional_kwargs={}, example=False)],
'answer': 'Agent-based modeling (ABMs) is a computational simulation ...
... requiring careful planning and execution.'
Let's ask a subsequent question...
query = "Give an example application for it."
result = qa({"question": query})
This time the question was reformulated before the semantic search in chroma as 'Can you provide an example of an application for agent-based modelling?'. The result contains the expected chat history:

You can tweak that chain for example by using different LLMs for the 2 chains, reformulating the prompts, changing the behaviour of the chains (e.g. how to combine the documents? do we still ask the original question with the documents and conversation history? or do we use the reformulated question without the conversation history?... ). You'll have to see what gives good answer quality while meeting your requirements in terms of cost (number of tokens, cheaper LLM...), performance etc.
Beyond that example, Langchain offers chain composition tools such as SequentialChain. For example, take as input a series of articles, summarize them and feed the summary to another LLM to analyze the sentiment.
Next
I hope you enjoyed reading about chains! Next we will discuss how to create agents: how to give LLMs the ability to build reasoning loops and use tools to achieve an objective.
References
Accessed 15/09/2023:
How to formulate great prompts for openai: https://help.openai.com/en/articles/6654000-best-practices-for-prompt-engineering-with-openai-api
Chains in Langchain: https://python.langchain.com/docs/modules/chains
Semantic search and RAG workflow: https://isabelle.hashnode.dev/knowledge-qa-using-retrieval-augmented-generation-rag